资源简介
一个可以离线运行的本地语音识别转文字工具,基于 fast-whipser 开源模型,可将视频/音频中的人类声音识别并转为文字。可输出json格式、srt字幕带时间戳格式、纯文字格式。可用于自行部署后替代 openai 的语音识别接口或百度语音识别等,准确率基本等同openai官方api接口。感兴趣的可以下载使用~
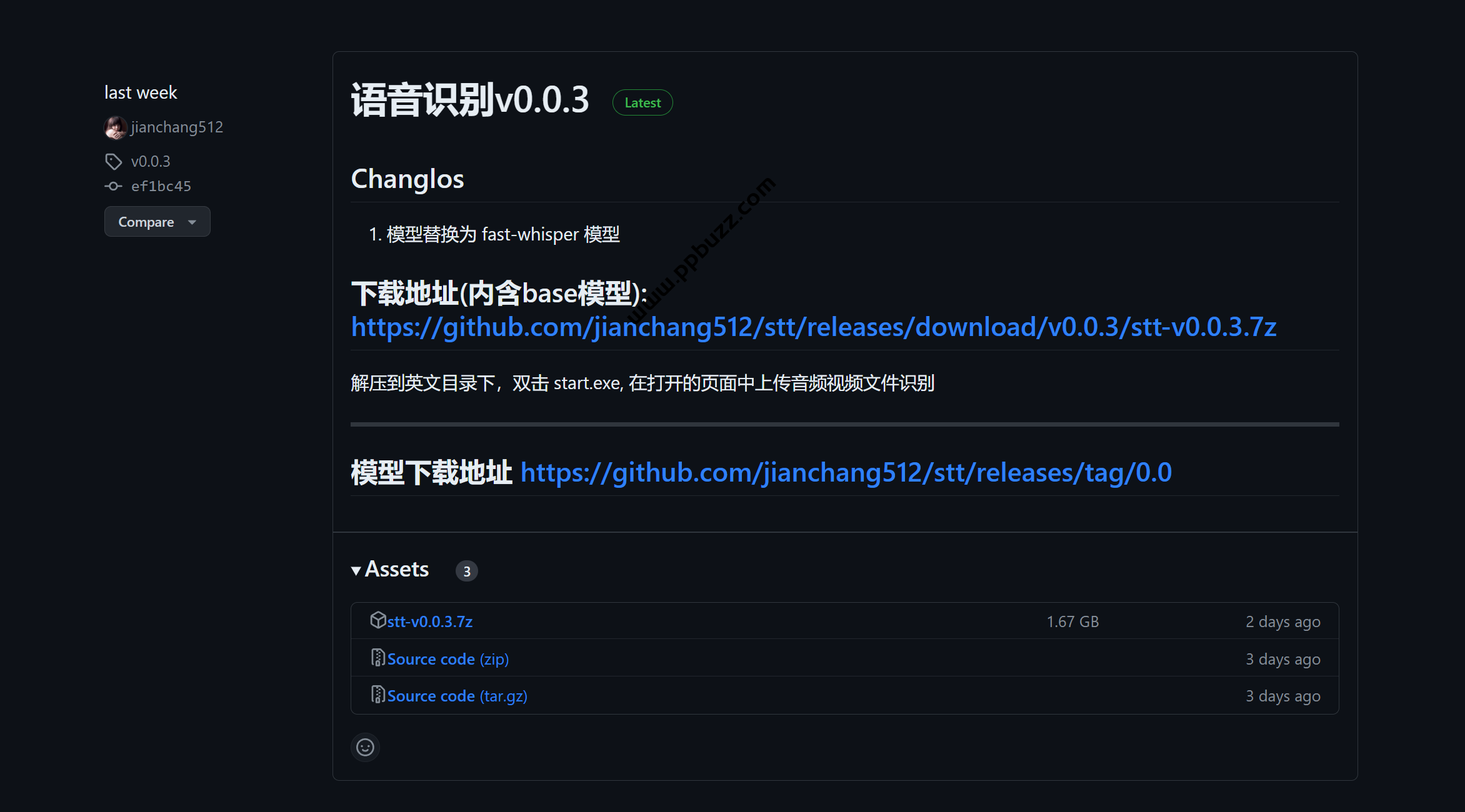
资源获取
github地址:https://github.com/jianchang512/stt/releases
直接下载:https://github.com/jianchang512/stt/releases/download/v0.0.3/stt-v0.0.3.7z
1. 转载请保留原文链接谢谢! 2. 本站所有资源文章出自互联网收集整理,本站不参与制作,如果侵犯了您的合法权益,请联系本站我们会及时删除。 3. 本站发布资源来源于互联网,可能存在水印或者引流等信息,请用户擦亮眼睛自行鉴别,做一个有主见和判断力的用户。 4. 本站资源仅供研究、学习交流之用,若使用商业用途,请购买正版授权,否则产生的一切后果将由下载用户自行承担。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。